大數(shù)據(jù)處理方法解析

在數(shù)字化時代,數(shù)據(jù)已成為企業(yè)和組織的核心資產(chǎn)。大數(shù)據(jù)的規(guī)模、多樣性和生成速度給傳統(tǒng)數(shù)據(jù)處理方法帶來了巨大挑戰(zhàn)。為了高效地從海量數(shù)據(jù)中提取價值,一系列專門的大數(shù)據(jù)處理方法應(yīng)運而生。本文將從數(shù)據(jù)采集、存儲、處理和分析四個關(guān)鍵環(huán)節(jié),介紹主要的大數(shù)據(jù)處理方法。
一、數(shù)據(jù)采集方法
數(shù)據(jù)采集是大數(shù)據(jù)處理的第一步,涉及從不同來源收集數(shù)據(jù)。常用方法包括:
- 批量采集:適用于周期性數(shù)據(jù)導(dǎo)入,如使用Apache Sqoop從關(guān)系數(shù)據(jù)庫批量遷移數(shù)據(jù)到Hadoop。
- 實時流采集:通過Kafka、Flume等工具實時捕獲流式數(shù)據(jù),滿足對即時數(shù)據(jù)的需求。
- 日志采集:利用ELK(Elasticsearch、Logstash、Kibana)等技術(shù)收集系統(tǒng)日志數(shù)據(jù)。
二、數(shù)據(jù)存儲方法
有效的存儲是處理大數(shù)據(jù)的基礎(chǔ),主要包括:
- 分布式文件系統(tǒng):如HDFS(Hadoop Distributed File System),支持存儲海量非結(jié)構(gòu)化數(shù)據(jù)。
- NoSQL數(shù)據(jù)庫:如MongoDB、Cassandra等,適用于非關(guān)系型數(shù)據(jù)的靈活存儲。
- 數(shù)據(jù)湖:如Amazon S3、Azure Data Lake,允許存儲原始數(shù)據(jù),支持后續(xù)多維度分析。
三、數(shù)據(jù)處理方法
數(shù)據(jù)處理是將原始數(shù)據(jù)轉(zhuǎn)化為可用信息的關(guān)鍵,主要方法有:
- 批處理:適用于離線分析,典型工具有MapReduce和Apache Spark,能高效處理大規(guī)模靜態(tài)數(shù)據(jù)集。
- 流處理:如Apache Storm、Flink,實時處理連續(xù)數(shù)據(jù)流,適用于監(jiān)控、實時推薦等場景。
- 圖計算:如圖數(shù)據(jù)庫Neo4j、處理框架GraphX,專門處理復(fù)雜關(guān)系數(shù)據(jù),如社交網(wǎng)絡(luò)分析。
四、數(shù)據(jù)分析方法
數(shù)據(jù)分析旨在從處理后的數(shù)據(jù)中提取洞察,常用方法包括:
- 數(shù)據(jù)挖掘:運用分類、聚類、關(guān)聯(lián)規(guī)則等技術(shù)發(fā)現(xiàn)隱藏模式。
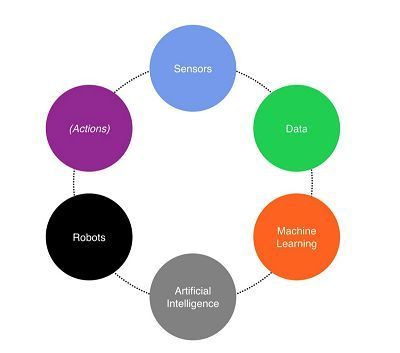
- 機(jī)器學(xué)習(xí):通過算法訓(xùn)練模型進(jìn)行預(yù)測和分類,如使用TensorFlow、Scikit-learn。
- 可視化分析:借助Tableau、Power BI等工具,將數(shù)據(jù)以圖表形式呈現(xiàn),便于理解。
大數(shù)據(jù)處理方法是一個多層次、多技術(shù)的體系。從采集到分析,選擇合適的方法需結(jié)合數(shù)據(jù)特性、業(yè)務(wù)需求和技術(shù)環(huán)境。隨著人工智能和云計算的發(fā)展,未來大數(shù)據(jù)處理將更智能、高效,為決策提供更強(qiáng)支持。
如若轉(zhuǎn)載,請注明出處:http://www.dxfl10.cn/product/8.html
更新時間:2026-01-08 02:29:50