離線數倉與實時數倉 軟件開發中的核心差異與應用場景
在當今數據驅動的軟件開發領域,數據倉庫(Data Warehouse)作為企業數據管理的核心基礎設施,扮演著至關重要的角色。根據數據處理和響應的時效性,數據倉庫主要分為離線數倉(Offline Data Warehouse)和實時數倉(Real-time Data Warehouse)兩種類型。它們在架構設計、技術選型、應用場景及開發流程上存在顯著差異。以下將詳細探討離線數倉與實時數倉在軟件開發中的區別。
一、數據處理時效性的差異
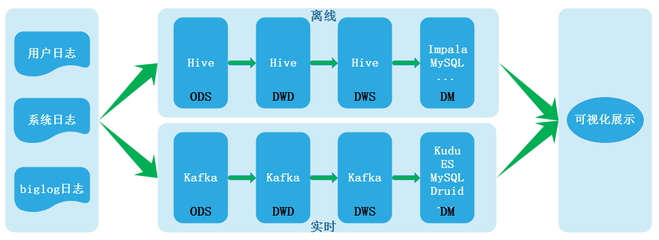
離線數倉通常采用批處理(Batch Processing)方式,數據采集、清洗、轉換和加載(ETL過程)在固定的時間間隔內完成,例如每天、每周或每月。這種模式適用于對實時性要求不高的場景,如歷史數據分析、報表生成和趨勢預測。開發離線數倉時,常用技術包括Hadoop、Hive、Spark等,這些工具能夠高效處理大規模數據,但延遲較高,數據從產生到可用可能需要數小時甚至更長時間。
實時數倉則強調低延遲和高吞吐,數據從源頭到分析結果的流轉幾乎是實時的,通常在秒級或分鐘級內完成。它采用流處理(Stream Processing)技術,適用于需要即時響應的應用,如金融風控、實時推薦系統和物聯網監控。在軟件開發中,實時數倉常依賴Kafka、Flink、Storm等框架,這些工具支持事件驅動架構,確保數據持續流入和處理。
二、架構設計與技術棧的對比
離線數倉的架構通常以數據湖(Data Lake)或分層結構(如ODS、DWD、DWS層)為基礎,數據流向呈周期性。開發過程中,重點在于優化批處理作業的性能和資源管理,例如使用Spark進行分布式計算,或通過Hive進行SQL查詢優化。這種架構簡化了數據一致性管理,但缺乏實時性。
實時數倉的架構則更復雜,往往結合了流處理引擎和消息隊列。數據從源端(如數據庫日志或傳感器)通過Kafka等消息中間件實時流入,再由Flink或Spark Streaming進行處理和存儲。軟件開發時,需考慮狀態管理、容錯機制和水平擴展,以應對高并發和數據丟失風險。實時數倉常與OLAP數據庫(如ClickHouse或Druid)集成,以支持快速查詢。
三、應用場景與業務需求的適配
離線數倉在軟件開發中主要用于離線分析和決策支持。例如,電商平臺可使用離線數倉分析用戶歷史購買行為,生成月度銷售報表;或企業利用它進行數據挖掘,優化長期戰略。開發這類系統時,重點在于數據建模、ETL流程設計和性能調優,而對實時性要求較低。
實時數倉則適用于對時效性敏感的場景。例如,在金融領域,實時數倉可監控交易數據,快速檢測欺詐行為;在在線廣告中,它能根據用戶實時行為調整推薦內容。軟件開發中,實時數倉的挑戰在于保證數據準確性和系統穩定性,需要精細的監控和告警機制。
四、開發流程與維護成本的考量
從軟件開發流程來看,離線數倉的開發相對成熟和標準化。團隊可以遵循傳統的ETL管道設計,使用調度工具(如Airflow)自動化任務,并通過數據質量檢查確保可靠性。維護成本較低,因為批處理作業在非高峰時段運行,資源需求可預測。
實時數倉的開發則更具挑戰性,需要敏捷的迭代和持續集成。開發團隊必須處理流數據的無序性和重復問題,并實現高效的資源調度。維護成本較高,因為系統需7x24小時運行,且對網絡延遲和硬件故障更敏感。因此,實時數倉的軟件開發往往需要更多的測試和運維投入。
五、未來趨勢與融合方向
隨著大數據技術的發展,離線數倉和實時數倉的界限正在模糊。Lambda架構和Kappa架構的出現,允許企業在同一系統中結合批處理和流處理,從而平衡實時性與成本。在軟件開發中,開發者應評估業務需求,選擇或融合合適的方案。例如,采用數據湖倉一體化架構,既能處理歷史數據,又能支持實時查詢。
離線數倉和實時數倉在軟件開發中各有優劣。離線數倉適合對延遲不敏感的分析任務,開發注重穩定性和可擴展性;實時數倉則滿足即時決策需求,開發強調低延遲和高可用性。選擇哪種方案,需根據具體業務場景、資源約束和團隊能力綜合權衡。在日益復雜的數據環境中,掌握兩者的差異,將有助于開發更高效、可靠的數據驅動應用。
如若轉載,請注明出處:http://www.dxfl10.cn/product/9.html
更新時間:2026-01-08 13:27:55